

Refiérete a este notebook si ya sabes lo básico.
¿Por qué Aprendizaje Profundo?
Hace tiempo, estaba en una misión de aprender sobre el Aprendizaje Profundo (Deep Learning), específicamente el Aprendizaje Profundo Generativo. Mientras me introducía a un “reino vasto de recursos online”, me encontré con numerosos videos dedicados al Aprendizaje Profundo. Aún así, me di cuenta que solo había un par de tutoriales disponibles para el Aprendizaje Profundo Generativo en ese entonces (29 de mayo del 2023). Esos videos proporcionaron conocimientos invaluables para los conceptos matemáticos que se requieren, me di cuenta que la mayoría del tiempo se basaban en bibliotecas de alto nivel como TensorFlow y PyTorch, para implementar los programas.
Pero mi curiosidad no disminuyó. Quería construir mi propio programa desde cero para poder entender la esencia del Aprendizaje Profundo. Con la ayuda de tutoriales de YouTube y un poquito (en serio, un poquito) de conocimiento matemático, fui en una aventura para entender cómo las cosas funcionan. Esto me permitió descubrir el framework fundamental que sustenta el Aprendizaje Profundo, permitiéndome realmente entender sus complejidades y desatar mi potencial creatividad.
Conceptos Básicos del Aprendizaje Profundo
Vamos a construir un punto de modelo de clasificación y mientras lo hacemos, vamos a aprender acerca de las Redes del Aprendizaje Profundo.
Creación de Datos y Preprocesado: En este paso, vas a necesitar recopilar los datos y preprocesarlos para poder tener lecturas acertadas. El éxito y las fallas del modelo son grandemente determinados por los datos dados al modelo. Vamos a crear un simple dataset para nuestro modelo.
# Crea un array de números de x a y con un stp de x
# np.arange(x, y, z)
x_values = np.arange(-2500, 2500, 0.1)
y_values = np.arange(-25000, 25000, 1)
# mezcla la posición de los valores en el array
np.random.shuffle(x_values)
np.random.shuffle(y_values)
# Nuestra Función de Gráfico Parabólico
def parabola(x):
return round((0.8 * x**2) - 300*x + 50, 0)
dataset = []
for x, y in zip(x_values, y_values):
if y < parabola(x): # Los Puntos están dentro de la Parábola
label = 0
labels[0] += 1
else: # Los Puntos están Sobre o Fuera de la Parábola
label = 1
labels[1] += 1
dataset.append((x, y, label))
# Convertir la lista a array
dataset = np.array(dataset)
En la creación de datos, vamos a dividirlos en datos de prueba y entrenamiento. Los Datos de Entrenamiento son los datos usados mientras entrenamos el modelo mientras que los Datos de Prueba son los datos usados mientras probamos los datos (para el output final). Usualmente, los Datos de Prueba son pequeños comparados con los Datos de Entrenamiento y ambos se forman antes del Dataset.
# obteniendo la forma de los datos
m = dataset.shape[0]
# dividendo los datos en datos de prueba y entrenamiento
data_test = dataset[:1000].T
x_test = data_test[0:2]
y_test = data_test[2]
data_train = dataset[1000:m].T
x_train = data_train[0:2]
y_train = data_train[2]
Creando una Red Neuronal Profunda
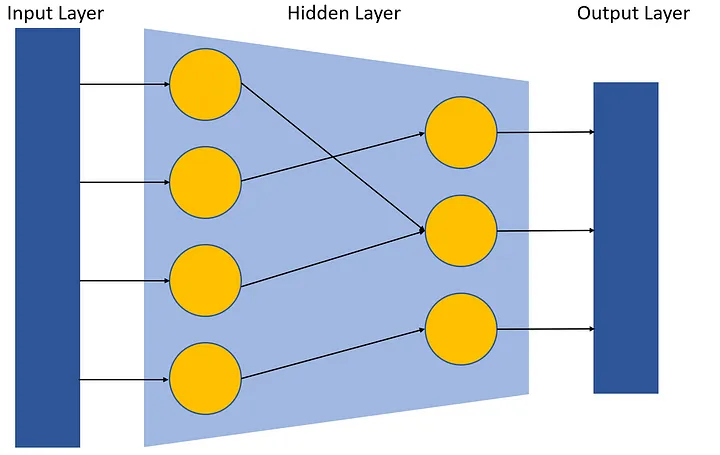
Cualquier Modelo de Aprendizaje Profundo se divide en 3 grandes partes:
- La Capa de Entrada (Input Layer)
- La Capa Oculta (Hidden Layer)
- La Capa de Salida (Output Layer)
Capa de Entrada
Esta es la capa donde todos tus datos pre-procesados se insertan. Esta capa, usualmente, no necesita ninguna atención especial dadas sus dimensiones, ya que deberíamos ser capaces de colocar cualquier datos dimensionales.
La Capa Oculta
La capa oculta en una red neuronal es una capa intermedia entre las capas de entrada y salida. Juega un rol crucial en capturar patrones complejos y característicos de los datos de entrada, permitiendo que la red aprenda y haga predicciones certeras.
La Capa de Salida
La capa de salida de una red neuronal es responsable de producir las predicciones finales o las salidas, basadas en la información aprendida en las capas anteriores. Típicamente consiste en una o más neuronas, cada una representando una clase específica o un valor de regresión, y la función de activación usada en la capa de salida depende de la naturaleza del problema que necesita ser resuelto.
Poniendo esto de lado, comencemos con la inicialización de los parámetros (pesos) de nuestra red neuronal.
# Inicializa los pesos y las bases del gráfico a un valor entre -0.5 y 0.5
def init_params():
W1 = np.random.rand(2, 2) - 0.5
b1 = np.random.rand(2, 1) - 0.5
W2 = np.random.rand(2, 2) - 0.5
b2 = np.random.rand(2, 1) - 0.5
return W1, b1, W2, b2
Ahora vamos a inicializar nuestras Funciones de Activación. Las Funciones de Activación juegan un rol íntegro en las redes neuronales, introduciendo la no-linealidad. Esta no-linealidad le permite a las redes neuronales a desarrollar representaciones complejas y funciones basadas en las entradas que no serían posible con un modelo de regresión lineal simple.
# Para este modelo, usaremos RelU y las Funciones Sigmoid
# Sus gráficos están dados abajos
# Son inicializados a continuación
def ReLU(Z):
return np.maximum(Z, 0)
def sigmoid(x):
return 1 / (1 + np.exp(-x))

Ahora, vamos a iniciar la propagación hacia adelante de nuestros modelos. La propagación hacia adelante (forward propagation) es el proceso de pasar datos de entradas a través de la red neuronal para computar las predicciones de salida o las activaciones de cada capa. Involucra multiplicar los datos de entrada de los pesos aprendidos, aplicando funciones de activación y propagando los resultados hacia adelante a través de la red.
# Z1 es el producto de los nodos y sus presos, añadidos a algunos bias
# A1 es la activación tomada por ReLU y Sigmoid
def forward_prop(W1, b1, W2, b2, X):
Z1 = W1.dot(X) + b1
A1 = ReLU(Z1)
Z2 = W2.dot(A1) + b2
A2 = sigmoid(Z2)
return Z1, A1, Z2, A2
Vamos ahora a codear algunas funciones utilitarias para la propagación hacia atrás (backward propagation). El ReLU_deriv (la función derivativa de ReLU) es la cuesta de las funciones ReLU en diferentes puntos. Es dado por la siguiente fórmula.

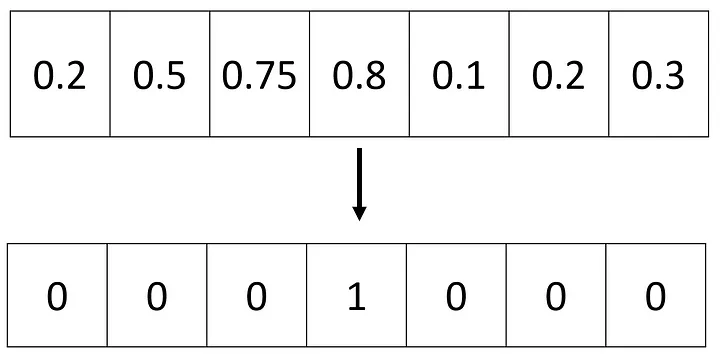
La codificación en caliente es una técnica popular usada en la machine learning para representar las variables categóricas como vectores binarios. Convierte una variable categórica en una matriz binaria dispersa donde cada columna corresponde a una categoría única y un valor de 1 indica la presencia de esa categoría.
def ReLU_deriv(Z):
return Z > 0
def one_hot(Y):
one_hot_Y = np.zeros((Y.size, int(np.ceil(Y.max()))))
one_hot_Y[np.arange(Y.size), np.ceil(Y).astype(int) - 1] = 1
one_hot_Y = one_hot_Y.T
return one_hot_Y
Vamos ahora a la Propagación hacia atrás. Es un paso clave en el entrenamiento de las redes neuronales. Involucra computar y actualizar los gradientes de los parámetros del modelo basados en los errores o pérdidas calculados desde el paso hacia adelante, permitiendo a la red a aprender y mejorar su performance con el tiempo.
def backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y):
one_hot_Y = one_hot(Y)
dZ2 = A2 - one_hot_Y
const = 1/m
dW2 = const * dZ2.dot(A1.T)
db2 = const * np.sum(dZ2)
dZ1 = W2.T.dot(dZ2) * ReLU_deriv(Z1)
dW1 = const * dZ1.dot(X.T)
db1 = const * np.sum(dZ1)
return dW1, db1, dW2, db2
Y ahora vamos a actualizar todos los pesos basados en los valores de cambio que recibimos donde la propagación hacia atrás.
def update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, learn_rate):
W1 = W1 - learn_rate * dW1
b1 = b1 - learn_rate * db1
W2 = W2 - learn_rate * dW2
b2 = b2 - learn_rate * db2
return W1, b1, W2, b2
Finalmente, podemos combinar todas nuestras funciones en una función gradiente descendiente y ver que la magia suceda. El gradiente descendiente es una optimización algorítmica usada para minimizar la pérdida de errores del modelo de la machine learning. Se ajusta iterativamente los parámetros del modelo en la dirección de descenso más pronunciado de la función de pérdida, acercándose gradualmente a los valores óptimos. Actualizando los parámetros basados en el gradiente de la pérdida, el descenso de la gradiente ayuda al modelo a convergir hacia una mejor solución.
# getPrediction y getAccuracy son funciones estandarizadas
def get_predictions(A2):
return np.argmax(A2, 0)
def get_accuracy(predictions, Y):
return np.sum(predictions == Y) / Y.size
# esta función de descenso de la gradiente es el paso final para entrenar a nuestro modelo
def gradient_descent(X, Y, alpha, iterations):
W1, b1, W2, b2 = init_params()
for i in range(iterations + 1):
Z1, A1, Z2, A2 = forward_prop(W1, b1, W2, b2, X)
dW1, db1, dW2, db2 = backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y)
W1, b1, W2, b2 = update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha)
if i % 25 == 0:
print("Iteration: ", i)
predictions = get_predictions(A2)
print(get_accuracy(predictions, Y))
return W1, b1, W2, b2
Y finalmente lo ejecutamos
# Aquí está el comando final para probar nuestro modelo
W1, b1, W2, b2 = gradient_descent(x_train, y_train, 0.10, 500)
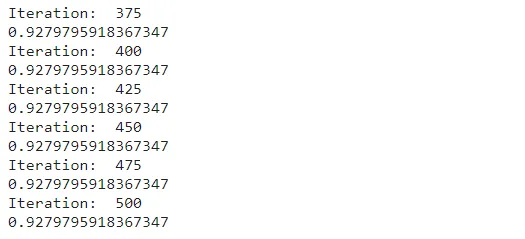
Despues de ejecutar la función final del descenso de la gradiente, obtendremos la puntería final de nuestros datos de entrenamiento, es decir, 0.02 o 92%. (Por cierto, puedes que tengas un valor ligeramente diferente por los patrones aleatorios en la inicialización). Si quieres incrementar la eficiencia, puedes intentarlo modificando la tasa de aprendizaje.
Ahora vamos a ver que tan certero son los datos de nuestros datos de prueba (recuerda, creamos esto al principio)
# predicciones de prueba
def make_predictions(X, W1, b1, W2, b2):
_, _, _, A2 = forward_prop(W1, b1, W2, b2, X)
predictions = get_predictions(A2)
return predictions
def test_prediction(index, W1, b1, W2, b2):
current_image = x_train[:, index, None]
prediction = make_predictions(x_train[:, index, None], W1, b1, W2, b2)
label = y_train[index]
print("Prediction: ", prediction)
print("Label: ", label)
dev_predictions = make_predictions(x_test, W1, b1, W2, b2)
get_accuracy(dev_predictions, y_test)

Un 92.6% de precisión en los datos que este modelo nunca ha visto (Test Data) es muy bueno, considerando que usamos dos capas juntas en nuestra Red Neuronal.
Felicitaciones a cualquiera que haya seguido y haya hecho esto junto a este artículo.
Conclusión
En este artículo, vimos cómo crear un Modelo simple de Aprendizaje Profundo desde cero, sin usar cualquier abstracción de bibliotecas de alto nivel para ayudarnos a entender completamente la forma en la funcionan estos Modelos de Aprendizaje Profundo.
Referencias
Quiero agradecer a todos los siguientes artículos y videos los cuales me refería mientras creaba este artículo:
- Samson Zhang Construye una red neuronal DESDE CERO
- AI Solutions Curso de Aprendizaje Profundo Completo (playlist)
- Alexander Amini Introducción MIT al Aprendizaje Profundo / 6.S191
- Learn with Apana Qué es AI Generativo/Diferencias entre IA e IA Generativo
Este artículo es una traducción de Steve Fernandes, hecha por Héctor Botero. Puedes encontrar el artículo original aquí.
Sería genial escucharte en nuestro Discord, puedes contarnos tus ideas, comentarios, sugerencias y dejarnos saber lo que necesitas.
Si prefieres puedes escribirnos a @web3dev_es en Twitter.




Discussion (0)