
La atención puede ser todo lo que necesitas, pero ¿realmente necesitas todo?

Imagen generada por DALL·E
En la era de la ingeniería de prompts, ¿todavía hay espacio para el entrenamiento y desarrollo de modelos, o debemos simplemente inclinarnos ante GPT y sus homólogos?
Los grandes modelos de lenguaje (LLM) se han vuelto increíblemente populares en los últimos años, con modelos como GPT generando texto similar al humano. En el fondo, estos modelos utilizan diferentes arquitecturas optimizadas para diferentes propósitos.
Aunque el modelo tradicional Codificador-Decodificador (ejemplificado por BERT de Google) es más complejo que sus equivalentes que son solo Decodificadores, GPT de OpenAI logra un rendimiento excepcional siguiendo la última configuración. ¿Cómo es que un modelo menos complejo es mejor que uno más complejo? Además, dadas las increíbles capacidades de GPT, podríamos sentirnos tentados a usarlo incluso para las tareas más básicas de PLN, como la clasificación de texto y el análisis de sentimientos. Pero, ¿deberíamos hacerlo?
En este artículo, veremos cómo se utiliza la arquitectura del modelo que introdujo los fundamentos de la atención y los transformadores, y cómo podemos descomponerla para obtener resultados mejores y más viables para cada caso de uso específico.
Modelos Transformador y Codificador-Decodificador
La arquitectura del Codificador-Decodificador consta de dos componentes principales: un codificador y un decodificador (obviamente). Los modelos Codificador-Decodificador se utilizan normalmente en tareas de secuencia a secuencia, como la traducción y la síntesis. El modelo Transformer (Transformador), propuesto en el famoso artículo "Attention Is All You Need" [1], es una instancia específica de la arquitectura Codificador-Decodificador que utiliza mecanismos de autoatención para superar las limitaciones de modelos anteriores, como LSTMs y GRUs.
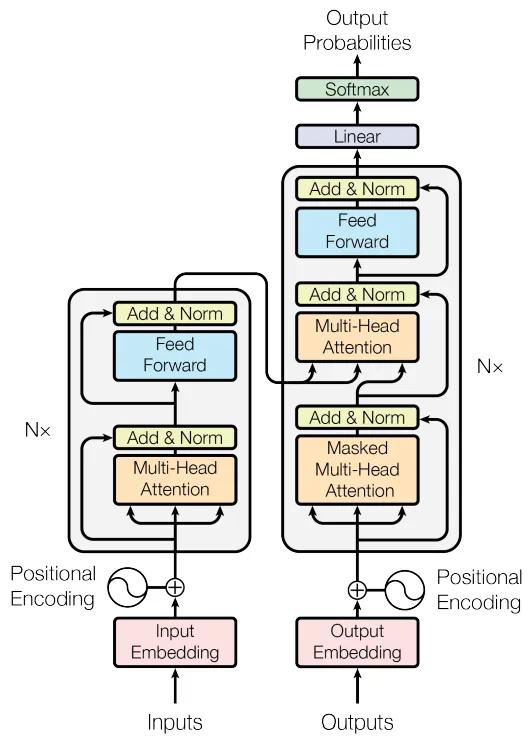
La arquitectura del Codificador-Decodificador Transformador (fuente: [1])
En la figura de arriba, el Codificador (Encoder) es el bloque de la izquierda y el Decodificador (Decoder) es el bloque de la derecha. El codificador recibe el texto de entrada y lo codifica en una representación vectorial densa. Podemos pensar en esta representación codificada como el significado semántico y el contexto de la entrada. El decodificador toma esa representación y genera el texto de salida, token por token. Es por eso que, en la figura, puedes ver las salidas (Outputs) siendo insertadas en el Decoder: esto representa los tokens de salida siendo insertados de nuevo, uno por uno. Naturalmente, el Decoder necesita saber cuándo comenzar y cuándo detenerse: esto se representa con tokens especiales que indican el inicio y el final de un texto.
Modelos Solo Codificadores
Los modelos solo con codificador contienen solo el componente del codificador. Estos modelos codifican el texto de entrada en una representación vectorial semántica, pero no generan ningún texto de salida. En lugar de conectar la salida del codificador a un decodificador, su salida se conecta a un cabezal entrenado para un caso de uso específico (normalmente no es la generación de texto).
Estos modelos son útiles para la extracción de características del texto. Se entrenan en tareas que no requieren el mapeo secuencia a secuencia. La salida final del codificador se puede utilizar de varias formas, dependiendo de la tarea, como clasificación de tokens, clasificación de secuencias o incluso como características para otros modelos de aprendizaje automático.
Un ejemplo de un modelo solo con Codificador es BERT [2]. Utiliza la parte del codificador del modelo original Transformador para generar una representación de tamaño fijo de una secuencia de texto de entrada, que luego se puede ajustar para diversas tareas, como clasificación de texto y reconocimiento de entidades con nombre. Dado que el BERT utiliza solo el componente del codificador, no es inherentemente adecuado para tareas secuencia a secuencia fuera de lo común, a diferencia de la arquitectura completa del Transformador Codificador-Decodificador. En su lugar, el BERT se utiliza generalmente para tareas que requieren la comprensión del contexto de tokens individuales en una secuencia de texto.
Modelos Solo Decodificadores
Los modelos solo Decodificadores, como GPT [3, 4], contienen solo la parte del decodificador. La entrada para los modelos solo Decodificadores, es una secuencia de tokens que sirve como contexto para la generación de tokens subsiguientes.
Mientras que los Transformadores tradicionales (Codificador-Decodificador) se entrenan para tareas de secuencia a secuencia, los modelos solo con Decodificador se entrenan para predecir el siguiente token en una secuencia, dados los tokens anteriores. Estos modelos son normalmente auto-regresivos, lo que significa que generan el texto de salida token por token, condicionando el siguiente token a los tokens generados previamente. Esto difiere del Codificador-Decodificador tradicional, donde el codificador procesa toda la secuencia de entrada de una sola vez, y el decodificador genera la secuencia de salida token por token.
Los modelos solo Decodificadores se utilizan normalmente para tareas que requieren la generación de texto u otros tipos de datos a partir de algún contexto inicial. Esto incluye el rellenado de texto, la generación de texto e incluso tareas como la generación de imágenes en el caso de modelos como DALL-E [5].
Debido a que solo incluyen el decodificador, estos modelos pueden tener menos parámetros que un Transformer completo que incluye un codificador y un decodificador. Sin embargo, modelos como GPT-3 y GPT-4 han demostrado que las arquitecturas solo de decodificación se pueden dimensionar a un gran número de parámetros.
¿Por qué no utilizar GPT para todo?
Bueno, podrían. En la mayoría de los casos, los modelos tipo GPT pueden generar texto con éxito y comprender el contexto sin necesidad de un codificador a su lado. Además, estamos convencidos empíricamente de que estos modelos también pueden llevar a cabo tareas como la clasificación de texto y el análisis de sentimientos con una alta precisión: al proporcionar al GPT una indicación adecuada, sus capacidades son casi infinitas. Pero, como ocurre con todas las cosas maravillosas, no es gratuito. De hecho, todo lo contrario.
La tabla a continuación muestra cómo BERT puede obtener mejores resultados que GPT, especialmente para tareas semánticas y de clasificación (para obtener más información sobre el conjunto de datos y el punto de referencia utilizado, consulte [6]). Tenga en cuenta que esta referencia se refiere a la primera versión de GPT, no a la más reciente.
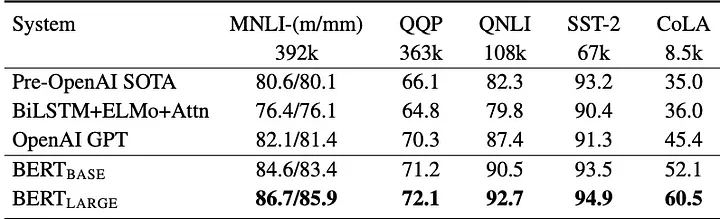
Comparación de BERT con GPT (Fuente: [2])
Como científicos de datos, debemos tomar una decisión. Y la elección depende de la aplicación final. Elegir una solución de Codificador-Decodificador solo porque proporciona una alta precisión puede aumentar innecesariamente el tiempo y el costo de desarrollo de un proyecto. Lo mismo se aplica a la elección de un modelo solo de Decodificadores como GPT: aunque puede clasificar texto o detectar sentimientos en frases, tiene el costo de ser un modelo enorme. Para soluciones básicas, como clasificación de texto y análisis de sentimientos, los modelos solo de Codificadores pueden ser una solución interna adecuada y de bajo costo.
Resumen
En cuanto a su funcionamiento interno:
Los codificadores extraen el significado semántico y el contexto del texto, generando una representación de ellos.
Los decodificadores generan texto a partir de texto, prediciendo cuál es la próxima palabra más probable, dada la anterior.
Al unir fuerzas, un modelo Codificador-Decodificador genera texto extrayendo primero un significado semántico y un contexto de una entrada (usando el Encoder) y luego prediciendo palabras una por una utilizando una combinación de estos significados y la palabra anterior que acaba de ser predicha (usando el Decoder).
Los modelos Codificadores-Decodificadores ofrecen una mayor flexibilidad, pero son más lentos de entrenar. Se utilizan para tareas como traducción y resumen.
Los modelos solo con Codificadores son eficientes para la clasificación y la extracción de características, pero no pueden generar texto.
Los modelos solo con Decodificadores son hábiles en la generación de texto, como en conversaciones.
Referencias
1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems.
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding.
[3] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
[4] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners.
[5] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., & Sutskever, I. (2021). DALL·E: Creating images from text
[6] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP.
Este artículo fue escrito por Gennaro S. Rodrigues y traducido por Juliana Cabeza. Su original se puede leer aquí



Discussion (0)